2月4日消息,今日,SuperCLUE发布了2025年度中文大模型基准测评报告。
23个国内外模型参与竞争,涵盖数学推理、科学推理、代码生成等六大核心维度。
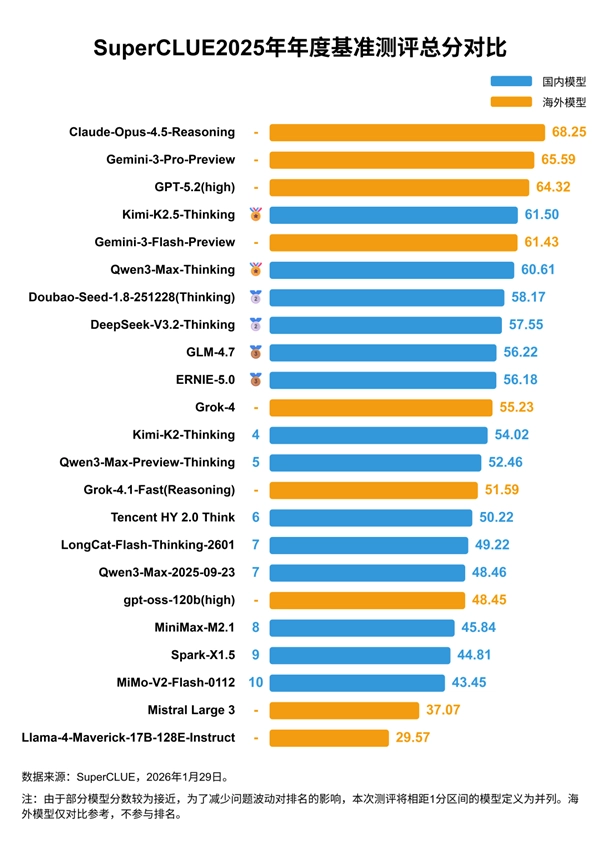
从结果来看,海外闭源模型依旧占据头部位置,Anthropic旗下的Claude-Opus-4.5-Reasoning以68.25分位居榜首。
谷歌的Gemini-3-Pro-Preview和OpenAI的GPT-5.2(high)分别以65.59分、64.32分紧随其后,包揽前三名。
不过,国产大模型正加速从跟跑向并跑迈进。国内开源最佳模型Kimi-K2.5-Thinking 和闭源最佳模型Qwen3-Max-Thinking,分别以61.50分、60.61分位列全球第四和第六。
在部分细分领域,国产模型表现亮眼,比如Kimi-K2.5-Thinking在代码生成任务中以53.33分夺冠,Qwen3-Max-Thinking在数学推理任务中与Gemini-3-Pro-Preview同获80.87分,并列全球第一。
从整体格局来看,海内外的开源与闭源模型存在显著差异。在闭源领域,海外处于领先地位,国产模型则在奋力追赶;而在开源领域,情况恰好相反,国内占据主导,海外则相对式微,国内开源模型的前五名在表现上均大幅领先于海外的开源模型。